2. Datos de investigación abiertos y materiales
¿En qué consisten?
Los datos de investigación abiertos son datos de acceso gratuito que pueden ser reutilizados, remezclados y redistribuidos para la investigación académica y la docencia, entre otros usos. Idealmente, los datos abiertos no tienen restricciones para su reutilización y redistribución y cuentan con licencias acordes a ello. En casos excepcionales (por ejemplo, para proteger la identidad de sujetos humanos), se pueden incluir restricciones de acceso especiales o limitadas. Compartir los datos de manera abierta facilita su examen, supone la base para la reproducibilidad y verificación de la investigación, y abre un camino para promover la colaboración. Como máximo, los datos abiertos pueden estar sujetos a los requisitos de atribución y de compartir igual (sharealike) (ver el Open Data Handbook)
Justificación
Los datos de investigación son a menudo el producto más valioso de los proyectos de investigación, pues se utilizan como fuente primaria para sustentar la investigación científica y permitir la derivación de hallazgos teóricos o aplicados. Para hacer que los hallazgos/estudios sean replicables, o al menos reproducibles o reutilizables de otra forma (consulta la sección sobre Investigación reproducible y análisis de datos), la recomendación de buenas prácticas es que los datos de investigación sean tan abiertos y tan (FAIR) como sea posible, teniendo en cuenta las limitaciones éticas y comerciales y las restricciones de privacidad de los datos confidenciales o privados.
![]()
Objetivos del aprendizaje
Obtener una comprensión de las características y principios básicos de los datos de investigación abiertos y datos FAIR (FAIR), incluyendo el empaquetado y la documentación apropiados, para permitir que otros los entiendan, reproduzcan y reutilicen de distintas maneras.
Familiarizarse con los tipos de datos que pueden considerarse confidenciales y las restricciones legales para compartirlos en abierto.
Ser capaz de convertir un conjunto de datos "cerrado" en uno "abierto" mediante la implementación de las medidas necesarias plasmadas en un plan de gestión de datos, administrando adecuadamente los datos y metadatos.
Ser capaz de utilizar un plan de gestión de datos de investigación y hacer que los resultados de tu investigación sean localizables y accesibles, incluso si contienen datos confidenciales.
Comprender las ventajas y desventajas de compartir en abierto diferentes tipos de datos (por ejemplo, referidas a la privacidad, confidencialidad, anonimización, y acceso mediado).
Comprender la importancia de la adecuación de los metadatos para el archivo sostenible de datos de investigación.
Comprender los flujos de trabajo básicos y las herramientas para compartir los datos de investigación.
Componentes clave
Conocimiento y habilidades
Principios FAIR (FAIR principles)
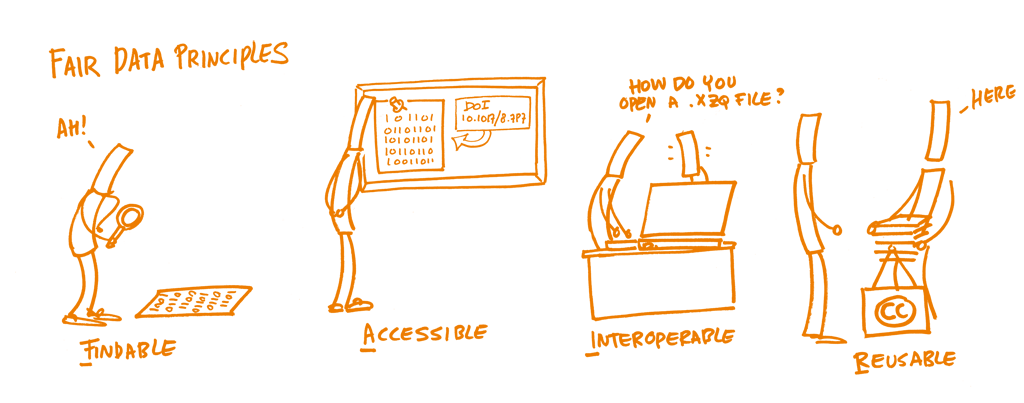
En 2014 se redactó un conjunto de principios para optimizar la reutilización de los datos de investigación. Fue denominado FAIR Data Principles. Los principios representan un conjunto de directrices y buenas prácticas desarrolladas por los propios académicos para garantizar que los datos (o cualquier objeto digital) sean Findable (localizables), Accessible (accesibles), Interoperable (interoperables) y Re-usable (reutilizables):
Localizables: Para que los datos sean reutilizables, primero se deben localizar. Debería ser fácil encontrar los datos y los metadatos tanto para humanos como para las computadoras. El descubrimiento automático y fiable de conjuntos de datos y servicios depende de los identificadores persistentes (PIDs) legibles por máquinas y de sus metadatos.
Accesibles: Los datos y metadatos deberían poder ser recuperados mediante su identificador utilizando un protocolo de comunicaciones abierto y estandarizado, que posiblemente incluya autenticación y autorización. Además, los metadatos deberían estar disponibles incluso si los datos ya no lo están.
Interoperables: Los datos deberían poder combinarse y usarse con otros datos o herramientas. Por lo tanto, el formato de los datos debe ser abierto e interpretable por distintas herramientas, incluyendo otros registros de datos. El concepto de interoperabilidad se aplica tanto en el nivel de los datos como en el de los metadatos. Por ejemplo, los (meta)datos deberían emplear un vocabulario que siga los principios FAIR.
Reutilizables: En última instancia, los principios FAIR buscan optimizar la reutilización de los datos. Para lograr esto, los metadatos y los datos deben estar bien descritos de modo que puedan ser replicados y/o combinados en diferentes entornos. Además, la reutilización de los (meta)datos debe estar indicada a través de licencias claras y accesibles.
A diferencia de las iniciativas entre pares que se centran en el investigador como humano, los principios FAIR ponen un énfasis específico en mejorar la capacidad de las máquinas para encontrar y utilizar automáticamente los datos o cualquier objeto digital, además de apoyar su reutilización por parte de los individuos. Los principios FAIR son principios rectores, no estándares. FAIR describe las cualidades o comportamientos necesarios para hacer que los datos sean reutilizables al máximo (por ejemplo: descripción, cita). Esas cualidades se pueden lograr con diferentes estándares.
Publicación de datos
La mayoría de los investigadores está más o menos familiarizado con la publicación en Acceso Abierto de artículos de investigación y libros (véase el capítulo 5). Más recientemente, y por las razones mencionadas anteriormente, la publicación de datos ha cautivado la atención. Cada vez más los organismos financiadores de investigación esperan que los datos producidos en los proyectos de investigación que financian sean fáciles de encontrar, sean accesibles y lo más abiertos posible.
Hay diferentes formas para hacer que los datos de investigación sean accesibles, incluyendo (Wikipedia):
Publicar los datos como material complementario asociado a un artículo de investigación. Generalmente los archivos de datos serán alojados por la editorial del artículo.
Alojar los datos en un sitio web de disponibilidad pública que permita acceder a los archivos para su descarga.
Depositar los datos en un repositorio diseñado para la la publicación de datos, por ejemplo, Dataverse, Dryad), figshare, Zenodo.
Existen un gran número de repositorios de datos generalistas y temáticos propios de alguna disciplina que pueden proporcionar apoyo adicional a los investigadores en el momento de depositar sus datos.
Publicar un artículo de datos (data paper) sobre el conjunto de datos, que podría publicarse como un preprint, en una revista, o en una revista de datos dedicada a publicar artículos de datos. Los datos pueden ser alojados por la revista o alojados por separado en un repositorio de datos. Algunos ejemplos de revistas de datos son Scientific Data (de SpringerNature) y Data Science Journal (de CODATA). Para una revisión integral de las revistas de datos, consulta Candela et al.
La Guía de Expertos en Gestión de Datos - CESSDA ERIC proporciona una perspectiva de las ventajas y desventajas de las diferentes rutas para la publicación de datos. A veces, tu financiador u otro organismo externo te requerirá que utilices un repositorio específico. Si puedes elegir libremente, puedes considerar el orden de preferencia sugerido en las recomendaciones de OpenAIRE:
Utiliza un archivo de datos externo o repositorio ya establecido en tu área de investigación para preservar los datos de acuerdo con estándares reconocidos en tu disciplina.
Si está disponible, usa un repositorio de datos de investigación institucional o la infraestructura de administración de datos de tu grupo de investigación.
Utiliza un repositorio de datos gratuito como por ejemplo Dataverse, Dryad, figshare o Zenodo.
Busca otros repositorios de datos en re3data. No hay una única opción de filtro en re3data que cubra los principios FAIR, pero teniendo en cuenta las siguientes opciones de filtro podrás encontrar repositorios compatibles con los principios FAIR: tipo de acceso, licencias de uso de datos, repositorios de datos fiables (con un certificado, o bien que explícitamente mencionen los estándares para el archivo) y si un repositorio asigna a los datos un identificador persistente (PID). Otro aspecto a considerar es si el repositorio admite el control de versiones.
Deberías considerar dónde depositar y publicar tus datos en el plan de gestión de datos de investigación. CESSDA ofrece algunas cuestiones a tener en cuenta. Por ejemplo: ¿Qué datos y metadatos asociados, documentación y código serán depositados? ¿Durante cuánto tiempo deben conservarse los datos? ¿Por cuánto tiempo deben permanecer reutilizables los datos? ¿Cómo estarán disponibles los datos? ¿Qué tipo de acceso se elegirá? Para más preguntas, consulta Adap your DMP: parte 6. Por otro lado, no se debe olvidar verificar si el repositorio elegido cumple con los requisitos de tu investigación y de tu financiador. Algunos repositorios ya han obtenido una certificación, como CoreTrustSeal, que los certifica como confiables y capaces de cumplir con los Requisitos Centrales para Repositorios de Datos Fiables (Core Trustworthy Data Repositories Requirements). Vale la pena mencionar que algunos repositorios de dominio específico pueden aceptar únicamente datos de alta calidad, con potencial para la reutilización y que pueden compartirse públicamente.
Dado que hay varias rutas para publicar tus datos, debes tener en cuenta que para que un conjunto de datos "cuente" como una publicación debe seguir un proceso de publicación similar al de un artículo (Brase et al., 2009) y debería:
Estar adecuadamente documentado con metadatos
Revisarse en relación con su calidad (por ejemplo: contenido del estudio, metodología, relevancia, consistencia legal y documentación de los materiales)
Permitir su búsqueda y ser localizable en catálogos o bases de datos (o bases de datos)
Ser citable en artículos
Citación de datos
Los servicios de indexación de datos sirven de ayuda a los grupos de investigación para descubrir, identificar y citar datos de investigación (y a menudo otros objetos de investigación) con confianza. Esto implica, generalmente, la creación y asignación de identificadores de objetos digitales (DOIs) y metadatos, recuperables a través de servicios como DataCite, que puede integrarse con otros flujos de investigación y estándares. Este es un campo emergente e involucra aspectos tales como transmitir a las editoriales de revistas la importancia de la cita apropiada de los datos en los artículos, como también permitir que los artículos de investigación se vinculen a los datos subyacentes. De esta manera, los datos citables se convierten en contribuciones legítimas al proceso de comunicación académica, y pueden ayudar a allanar el camino para nuevas métricas y modelos de publicación que reconozcan y recompensen el intercambio de datos.
Como paso inicial hacia una buena práctica para la cita de datos, el Data Citation Synthesis Group de FORCE11 ha elaborado la Declaración Conjunta de Principios para la Cita de Datos Joint Declaration of Data Citation Principles, dirigida a investigadores y proveedores de servicios de datos. Al adherirse a estos principios, los repositorios de datos generalmente proporcionan a los investigadores la referencia bibliográfica de como citar cuando se refieren a un set de datos específico.
Empaquetamiento de datos
Los paquetes de datos son contenedores para describir y compartir archivos de datos, y generalmente incluyen un archivo de metadatos que describe las características y el contexto de un conjunto de datos. Esto puede incluir aspectos tales como información de su creación, procedencia, tamaño, tipo de formato, definiciones de campos, así como cualquier otro archivo contextual relevante, como scripts de creación de datos o documentación textual. De acuerdo con la Guía para el Empaquetado de Datos:
Los datos son para siempre: los conjuntos de datos sobreviven a su propósito original. Las limitaciones de los datos pueden ser obvias dentro de su contexto original, como un catálogo de biblioteca, pero pueden no ser evidentes una vez que los datos se han separado del entorno para el que se crearon.
Los datos no pueden ser autosuficientes: la información sobre el contexto y la procedencia de los datos (cómo y por qué se creó, qué objetos y conceptos del mundo real representan, las limitaciones de sus valores) es necesaria para ayudar a los consumidores a interpretarlos de manera responsable.
La estructuración de metadatos sobre conjuntos de datos de una manera estándar y legible por máquinas fomenta la promoción, la capacidad de intercambio y la reutilización de los datos.
Cómo compartir datos confidenciales o privados
Con una planificación adecuada de la gestión de datos, los datos confidenciales y privados pueden compartirse, reutilizarse y ser FAIR. Los metadatos casi siempre pueden compartirse.La forma y las prácticas para compartir datos confidenciales están reguladas en función de la regulación propia de cada región (véase, por ejemplo, el Companion material for Managing and Sharing Research Data handbook del UKDS). La Asociación Internacional de Servicios y Tecnología de la Información en Ciencias Sociales (International Association for Social Science Information Services and Technology) mantiene una lista de guías internacionales sobre gestión de datos que es un buen punto de partida. Hay diferentes enfoques e iniciativas para ayudar a los investigadores a lograr esto. La herramienta DCC's DMPonline incluye plantillas que cumplen con los requisitos de financiadores de proyectos de investigación. La Guía de Expertos en Gestión de Datos CESSDA proporciona información y ejemplos prácticos sobre cómo compartir datos personales, temas relacionados con derechos de autor y con las bases de datos en países europeos. La Guía también ofrece una descripción general del impacto del GDPR que armoniza la legislación sobre datos personales en Europa (mayo de 2018) y proporciona una visión general actualizada sobre la diversidad en la UE en materia de protección de datos.
Broker de datos
Los broker de datos son entidades reconocidas e independientes que velan por los datos confidenciales. Los investigadores pueden transferir sus datos confidenciales y las posibles restricciones al acceso a los datos en función de su jurisdicción. Esto es especialmente común con los datos procedentes de pacientes de estudios clínicos. Estas entidades garantizan la independencia en la evaluación sobre qué datos son cientificamente válidos a la vez que aseguran la inviolabilidad de la privacidad de los participantes de la investigación Algunos ejemplos de intermediarios de datos son The YODA Project, ClinicalStudyDataRequest.com, National Sleep Research Resource y Supporting Open Access for Researchers (SOAR).
Portales de análisis
Los portales de análisis son plataformas que aprueban el análisis de datos sin que se permita el pleno acceso (visualización o descarga) o controlando desde dónde y quién tiene acceso. Algunos intermediarios de datos también usan portales de análisis. Los portales de análisis controlan qué conjuntos de datos adicionales se pueden combinar con los datos confidenciales, así como qué análisis se pueden ejecutar para garantizar que la información personal no se revele durante el nuevo análisis. Algunos ejemplos de portales de análisis virtuales son Project Data Sphere, Vivli, RAIRD, Corpuscle, y INESS.
Las investigadores de ciencias sociales o de otra disciplina que emplean datos confidenciales usan generalmente un portal único para el análisis dónde se accede mediante un régimen controlado. Los investigadores autorizados pueden acceder a los datos de forma segura con fines científicos. Sin embargo, los metadatos que describen los datos deben estar disponibles en abierto y cumplir con los principios FAIR.
Datos no identificables y sintéticos
Muchos conjuntos de datos que contienen información privada de participantes pueden compartirse una vez que el conjunto de datos no sean identificables los individuos (Método de Puerto Seguro) (Safe Harbor Method) o un experto determine que el conjunto de datos no sea identificable a nivel individual (método de determinación experta). Consulta con tu Comité de Ética de la Investigación / Junta de Revisión Institucional para saber cómo hacer esto con tus datos. También recomendamos la Guía de Expertos en Gestión de Datos CESSDA, que proporciona información y ejemplos prácticos sobre cómo compartir datos personales. Los investigadores pueden, no obstante, mejorar la apertura de la investigación sobre los datos mediante la creación y el intercambio de datos sintéticos. Los datos sintéticos son similares en estructura, contenido y distribución a los datos reales y aspiran a obtener "validez analítica": los análisis estadísticos arrojarán los mismos resultados con los datos sintéticos que con los datos reales. La Oficina del Censo de los Estados Unidos (United States Census Bureau), por ejemplo, utiliza portales de datos sintéticos y de análisis de manera combinada para permitir la reutilización de datos altamente sensibles.
Etiquetado de datos (DataTags)
DataTags es un marco digital que permite asesorar sobre las restricciones legales, contractuales y políticas que rigen las decisiones sobre el intercambio de datos. El sistema DataTags hace a un usuario una serie de preguntas para determinar las propiedades clave de un conjunto de datos y aplica reglas inferenciales para determinar qué leyes, contratos y buenas prácticas son aplicables. El resultado es un conjunto de DataTags recomendados, o etiquetas simples e icónicas que representan una política de datos legible por humanos y utilizable por máquinas, y un acuerdo de licencia a medida para el conjunto de datos. El sistema DataTags está diseñado para integrarse con el software del repositorio de datos y también funciona como una herramienta independiente. DataTags se ha desarrollado en la Universidad de Harvard. En Europa, DANS está trabajando para ajustar DataTags a la legislación europea General Data Protection Regulation (GDPR) (cf. DANS GDPR DataTags).
Como se mencionó anteriormente, el objetivo final de compartir tus datos de investigación es hacerlos reutilizables al máximo. Para ello, antes de compartir datos debe gestionarlos de acuerdo con las mejores prácticas. Esto incluye, por ejemplo, la documentación y la elección de formatos de archivos y licencias abiertos. Puedes leer más sobre estos temas en Sección 4: Investigación reproducible y análisis de datos así como Sección 6: Licenciamiento abierto y formatos de archivo.
Materiales abiertos
Además de compartir los datos, la apertura de la investigación depende del intercambio de materiales. Los materiales que utilizan los investigadores son específicos de cada disciplina y, a veces, exclusivos de un laboratorio. A continuación se dan algunos ejemplos de materiales que puedes compartir, sin embargo, consulta con colegas de tu disciplina qué repositorios son los que utilizan. Cuando tengas materiales, datos y publicaciones del mismo proyecto de investigación compartidos en diferentes repositorios, haz una referencia cruzada con un enlace y un identificador único para que puedan localizarse fácilmente.
Reactivos
Un reactivo es una sustancia, compuesto o mezcla que se puede agregar a un sistema para crear una reacción química o de otro tipo. Los reactivos se pueden documentar en repositorios como Addgene, The Bloomington Drosophila Stock Center y ATCC para que sean fácilmente accesibles para otros investigadores. Licencia tus materiales para que puedan ser reutilizados por otros investigadores.
Protocolos
Un protocolo describe un registro formal u oficial de observaciones experimentales científicas en un formato estructurado. Deposita los protocolos virtuales para su citación, adaptación y reutilización empleando Protocolos.
Cuadernos, contenedores, software y hardware
El uso de la programación, la tecnología de contenedores y la virtualización ayudan al análisis reproducible. Además de compartir tu código y tus datos, también comparte tus cuadernos Jupyter, imágenes Docker u otros materiales de análisis o tipos de software. Comparte cuadernos con servicios abiertos como mybinder que permiten la visualización y ejecución pública de todo el bloc de notas de manera compartida. Los contenedores y los cuadernos se pueden compartir con Rocker o Code Ocean. El software y el hardware utilizados en tu investigación se deben compartir siguiendo buenas prácticas para su documentación, tal como se describe en la [Sección 3]. Los protocolos de sólo lectura deben depositarse en un registro de tu disciplina, como ClinicalTrials.gov y SocialScienceRegistry, o en un registro general como Open Science Framework. Muchas revistas, como Trials, JMIR Research Protocols o Bio-Protocol publican protocolos. Las mejores prácticas para publicar tu protocolo en acceso abierto son las mismas que para publicar tu informe en acceso abierto (mira la Sección 5).
Preguntas, obstáculos e interpretaciones erróneas comunes
P: "¿Es suficiente con hacer que mis datos estén disponibles de manera abierta?"
R: "No, la apertura es una condición necesaria pero no suficiente para una reutilización máxima. Los datos tienen que ser FAIR además de abiertos".
P: "¿Qué significan/implican los principios FAIR para diferentes partes interesadas/audiencias?"
R: "¡Este es un gran tema para discusión!"
Obstáculo: los investigadores pueden ser reacios a compartir sus datos porque temen que otros los reutilicen antes de haberlos aprovechado al máximo, o que otros podrían no entender completamente sus datos y, por lo tanto, hacer un mal uso de ellos.
(sugerido ) R: Puedes publicar tus datos con metadatos para que se puedan localizar, y establecer un período de embargo en los datos para asegurarte de que puedes publicar tus propios artículos primero.
P: "¿Implica mucho trabajo extra hacer que mis datos sean FAIR?"
R: "¡No necesariamente! Hacer que los datos sean FAIR no sólo es responsabilidad de los investigadores individuales sino de todo el grupo de investigadores. La mejor manera de garantizar que tus datos son FAIR es crear un Plan de Gestión de Datos y planificar todo de antemano. Durante la recolección y el procesamiento de datos sigue los estándares de tu disciplina y las medidas recomendadas por un repositorio.
P: "Quiero compartir mis datos. ¿Cómo debo licenciarlos?"
R: "Esa es una buena pregunta. Primero, piensa en quién posee la propiedad de los datos: un financiador de la investigación o una institución para la que trabajas. Luego, piensa en la autoría. La aplicación de una licencia adecuada a sus datos es crucial para hacerlos reutilizables. Para más información sobre las licencias, consulta la Sección 6: Licencias abiertas y formatos de archivo.
P: "No puedo hacer que mis datos estén disponibles de manera directa: son demasiado grandes para compartir de manera conveniente / tienen restricciones relacionadas con cuestiones de privacidad. ¿Qué debo hacer?"
R: "Debería hablar con expertos en repositorios disciplinares sobre cómo hacer que sus datos sean localizables y accesibles".
Resultados del aprendizaje
Conocer las características de los datos abiertos, y en particular los principios FAIR.
Estar familiarizado con algunos de los argumentos en favor y en contra de los datos abiertos.
Ser capaz de diferenciar y trabajar con datos confidenciales y datos abiertos/FAIR; estas dos categorías no son necesariamente incompatibles.
Ser capaz de transformar un conjunto de datos en uno que pueda compartirse en abierto (formato no propietario), cumpla con los estándares de los principios FAIR y esté diseñado para maximizar el acceso, la transparencia y la reutilización, y proporcione metadatos suficientes.
Conocer la diferencia entre datos primarios y procesados (o depurados), y la importancia de las etiquetas de versión.
Conocer los formatos de archivo más comunes y los estándares comunitarios para asegurar la máxima reutilización.
Ser capaz de crear un Plan de Gestión de Datos.
Lecturas adicionales
The FAIR Guiding Principles for scientific data management and stewardship: https://www.nature.com/articles/sdata201618
Guiding principles for Findable, Accessible, Interoperable, and Re-usable data publishing Version B1.0: https://www.force11.org/fairprinciples
The FAIR Data Principles explained https://www.dtls.nl/fair-data/fair-principles-explained/
GO FAIR Initiative: https://www.go-fair.org/
FAIR Metrics: http://fairmetrics.org/
Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud: https://doi.org/10.3233/ISU-170824
Making data sharing count: a publication-based solution (Gorgolewski et al., 2013).
Data reuse and the open data citation advantage (Piwowar and Vision, 2013).
Expert tour guide on data management https://www.cessda.eu/Research-Infrastructure/Training/Expert-tour-guide-on-Data-Management
Making Data Count (Kratz and Strasser, 2015).
CESSDA ERIC, "Citing your data"
5 ★ OPEN DATA, http://5stardata.info/en/