2. Données et Outils de la Recherche Ouverte
De quoi parle t-on ?
Les données de la recherche ouverte sont des données qui peuvent être librement consultées, réutilisées, remaniées et redistribuées pour les besoins de la recherche universitaire, de l'enseignement et pour d'autres usages. Idéalement, les données ouvertes ne comportent aucune restriction quant à leur réutilisation ou leur redistribution et sont soumises à des licences appropriées en tant que telles. Dans des cas exceptionnels, par exemple pour protéger l'identité d'individus, des restrictions spéciales ou limitées d'accès sont fixées. Le partage ouvert des données les expose à l'inspection, ce qui constitue la base de la vérification et de la reproductibilité de la recherche et ouvre la voie à une collaboration plus large. Tout au plus, les données ouvertes peuvent être soumises à l'obligation d'attribuer et de partager des données de la même manière (voir le Open Data Handbook).
Fondement
Les données de recherche constituent souvent le résultat le plus précieux de nombreux projets de recherche ; elles sont utilisées comme sources primaires qui sous-tendent la recherche scientifique et permettent d'en tirer des résultats théoriques ou appliqués. Afin de rendre les résultats/études réplicables, ou du moins reproductibles ou réutilisables (voir Recherche reproductible et Analyse de Données) d'une autre manière, la meilleure pratique recommandée est que les données de recherche soient aussi ouvertes et FAIR que possible, tout en respectant les contraintes éthiques, commerciales et la confidentialité des données sensibles ou propriétaires.
Objectifs de formation
Comprendre les caractéristiques et principes de base des données de recherche ouvertes et FAIR, y compris le format approprié et la documentation, afin de permettre à d'autres de comprendre, de reproduire et de réutiliser les données de différentes manières.
Se familiariser avec les types de données pouvant être considérées comme sensibles, ainsi que les restrictions ou contraintes liées au partage de celles-ci.
Être capable de convertir un jeu de données "fermé" en un jeu "ouvert" en mettant en œuvre les mesures nécessaires dans un plan de gestion des données, avec une gestion appropriée des données et des métadonnées.
Être capable d'utiliser le plan de gestion des données de recherche et de rendre les résultats de vos recherches faciles à trouver et accessibles, même s'ils contiennent des données sensibles.
Comprendre les avantages et inconvénients du partage ouvert de différents types de données (p. ex. confidentialité, sensibilité, anonymisation, accès négocié).
Comprendre l'importance des métadonnées appropriées pour l'archivage durable des données de recherche.
Comprendre les flux de travail et les outils de base pour le partage des données de recherche.
Éléments clés
Connaissances & Compétences
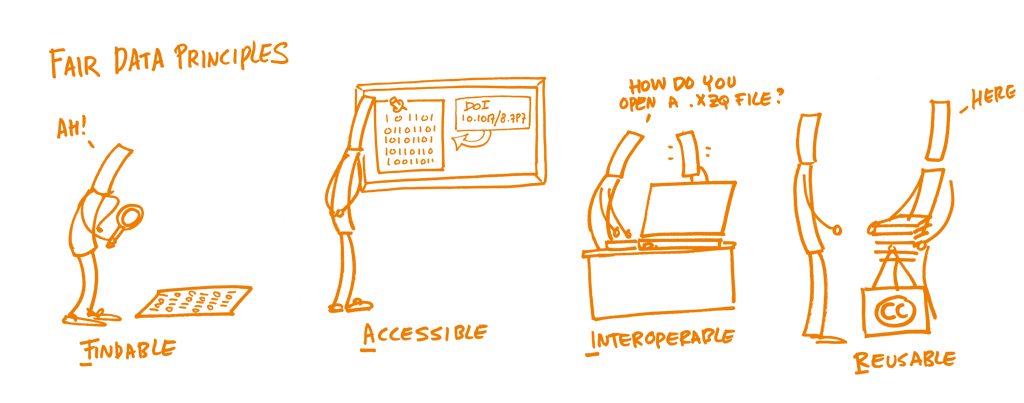
Principes FAIR
En 2014, un ensemble de principes a été rédigé afin d'optimiser la réutilisation des données de recherche, appelé les Principes des données FAIR. Il s'agit d'un ensemble de lignes directrices et de bonnes pratiques élaborées par la communauté afin de garantir que les données ou tout objet numérique soient Faciles à trouver, Accessibles, Interopérables et Réutilisables :
Facile à trouver : La première chose à faire pour rendre les données réutilisables est de faire en sorte qu'on puisse les trouver facilement. Il devrait être facile pour les humains et les ordinateurs, de trouver les données et leurs métadonnées. La découverte automatique et fiable des jeux de données et des services dépend d'identifiants pérennes et de métadonnées lisibles par des machines (PIDs pour persistent identifiers).
Accessible : Les (méta)données doivent pouvoir être consultables via leur identifiant à l'aide d'un protocole de communication standardisé et ouvert, incluant éventuellement une authentification et une autorisation. De plus, les métadonnées devraient être disponibles même lorsque les données ne le sont plus.
Interopérable : Les données doivent pouvoir être combinées et utilisées avec d'autres données ou outils. Le format des données devrait donc être ouvert et interprétable pour divers outils, y compris pour d'autres enregistrements de données. Le concept d'interopérabilité s'applique tant au niveau des données qu'à celui des métadonnées. Par exemple, les (méta)données devraient utiliser des vocabulaires qui suivent les principes FAIR.
Réutilisable : Pour finir, FAIR vise à optimiser la réutilisation des données. Pour y parvenir, les métadonnées et les données doivent être bien décrites afin qu'elles puissent être reproduites et/ou combinées dans différents contextes. De plus, la réutilisation des (méta)données devrait être déclarée par le biais d'une (de) licences claire(s) et accessible(s).
À la différence des initiatives entre pairs qui se concentrent sur l'intellect humain, les principes FAIR mettent l'accent sur l'amélioration de la capacité des machines à trouver et à utiliser automatiquement des données ou tout objet numérique, en plus de favoriser leur réutilisation par les individus. Les principes FAIR sont des lignes directrices et non des normes. Ils décrivent les qualités ou les comportements nécessaires pour que les données soient réutilisables au maximum (p. ex., description, citation). Ces qualités peuvent être atteintes par différentes normes.
Publication des données
La plupart des chercheurs sont plus ou moins familiers avec la publication en libre accès d'articles de recherche et d'ouvrages (voir chapitre 5). Plus récemment, et pour les raisons mentionnées ci-dessus, la publication de données a suscité un intérêt croissant. De plus en plus de financeurs s'attendent à ce que les données produites dans le cadre des projets de recherche qu'ils financent soient disponibles, accessibles et aussi ouvertes que possible.
Il existe plusieurs façons distinctes de rendre les données de recherche accessibles, notamment (Wikipedia) :
Publier les données en tant que matériel complémentaire associé à un article de recherche, généralement avec les fichiers de données hébergés par l'éditeur de l'article.
Héberger des données sur un site internet accessible au public, avec des fichiers disponibles pour téléchargement.
Déposer des données dans un entrepôt qui a été conçu pour la publication des données, p. ex. Dataverse, Dryad), figshare, Zenodo.
Il existe un grand nombre d'entrepôts de données généralistes et d'entrepôts de données spécifiques à un domaine ou à un sujet qui peuvent fournir un soutien supplémentaire aux chercheurs lorsqu'ils déposent leurs données.
Publier un data paper, article basé sur un jeu de données pouvant être publié sous la forme d'une prépublication (preprint), dans une revue ou dans un data journal dédié à la publication d'articles de données. Les données peuvent être hébergées par la revue ou séparément dans un entrepôt de données. Parmi les exemples de journaux de données, on trouve Scientific Data (par SpringerNature) et le Data Science Journal (par CODATA). Pour une étude complète de ce type de revues, voir Candela et al.
Le guide CESSDA ERIC Expert tour guide on Data Management donne un aperçu des avantages et des inconvénients des différentes options de publication des données. Parfois, votre financeur ou une autre tierce partie vous demandera d'utiliser un entrepôt spécifique. Si vous avez le libre choix vous pouvez prendre en compte l'ordre de préférence donné dans les recommandations d'OpenAIRE :
Utilisez une archive ou un entrepôt de données externe déjà établi dans votre domaine de recherche, afin de préserver les données conformément aux normes reconnues dans votre discipline.
Si disponible, utilisez un entrepôt de données de recherche institutionnel ou les infrastructures de gestion des données de votre groupe de recherche.
Utilisez un entrepôt de données gratuit tel que Dataverse, Dryad, figshare ou Zenodo.
Recherchez d'autres entrepôts de données dans re3data. Il n'y a pas d'option de filtrage spécifique dans re3data couvrant les principes de FAIR, mais prendre en compte les options de filtrage suivantes vous aidera à trouver des entrepôts compatibles FAIR : catégories d'accès, licences d'utilisation de données, référentiels de données fiables (avec un certificat ou respectant explicitement les normes d'archivage numérique) et si un référentiel fournit un identifiant pérenne aux données (PID). Un autre aspect à prendre en compte est de savoir si le référentiel supporte le versionnage.
Nous vous conseillons d'évaluer où déposer et publier vos données dès votre plan de gestion des données de recherche. Le CESSDA propose quelques questions pratiques qu'il est recommandé de se poser. Par exemple : Quelles données et métadonnées, documentation et code associés seront déposés ? Combien de temps les données doivent-elles être conservées ? Pendant combien de temps les données devront-elles rester réutilisables ? Comment les données seront-elles mises à disposition ? Quelle catégorie d'accès allez-vous choisir ? Pour plus de questions, consultez Adapt your DMP part 6. D'autre part, n'oubliez pas de vérifier que l'entrepôt choisi répond aux exigences de votre recherche et de votre financeur. Certains entrepôts ont déjà obtenu une certification, comme CoreTrustSeal, qui les certifie dignes de confiance et leur permet de répondre aux exigences des Trustworthy Data Repositories Requirements (Exigences des entrepôts de données dignes de confiance). Il convient de mentionner que certains entrepôts spécifiques à un domaine peuvent n'accepter que des données de haute qualité avec un potentiel de réutilisation et pouvant être partagées publiquement.
Etant donné qu'il existe plusieurs façons de publier vos données, vous devez noter que pour qu'un ensemble de données soit "comptabilisé" comme une publication, il devra suivre un processus de publication similaire à celui d'un article (Brase et al., 2009) et devra être :
Bien documenté avec des métadonnées ;
Revu par des pairs au niveau de sa qualité, par exemple du contenu de l'étude, de la méthodologie, la pertinence, la cohérence juridique et la documentation des documents ;
Indexés et consultable dans les catalogues (ou bases de données) ;
Citable dans les articles.
Citation des données
Les services de citation de données aident les communautés de recherche à découvrir, identifier et citer des données de recherche (et souvent d'autres objets de recherche) en confiance. Cela implique généralement la création et l'attribution de Digital Object Identifers (DOI) et de métadonnées d'accompagnement par le biais de services tels que DataCite, et la citation peut être intégrée aux flux de travail et normes de la recherche. Il s'agit d'un domaine émergent, qui implique des aspects tels que sensibiliser les éditeurs de revues à l'importance d'une citation appropriée des données dans les articles, ainsi que permettre aux articles de recherche eux-mêmes, de se relier à toutes données sous-jacentes. Ainsi, les données citables deviennent des contributions légitimes au processus de la communication savante et peuvent aider à ouvrir la voie à de nouvelles mesures d'impact et à de nouveaux modèles de publication qui reconnaissent et récompensent le partage des données.
Comme première étape vers de bonnes pratiques en matière de citation des données, le Groupe de synthèse sur la citation des données de FORCE11 a proposé la Joint Declaration of Data Citation Principles, destinée aux chercheurs et aux fournisseurs de services de données. En adhérant à ces principes, les dépôts de données fournissent habituellement aux chercheurs une référence qu'ils peuvent utiliser lorsqu'ils se réfèrent à un ensemble spécifique de données.
Les assemblages des données
Les assemblages de données (data packages) sont des conteneurs permettant de décrire et de partager les fichiers de données qui les accompagnent, et comprennent généralement un fichier de métadonnées décrivant les caractéristiques et le contexte d'un jeu de données. Cela peut inclure des aspects tels que les informations de création, la provenance, la taille, le type de format, les définitions de champs, ainsi que tous les fichiers contextuels pertinents, tels que les scripts de création de données ou la documentation textuelle. Extrait du Guide d'assemblage des données (Data Packaging Guide):
Les données sont éternelles : les jeux de données survivent à leur finalité initiale. Les limites des données peuvent être évidentes dans leur contexte original, comme un catalogue de bibliothèque, mais peuvent ne pas l'être une fois que les données sont séparées de l'application pour laquelle elles ont été créées.
Les données ne peuvent se suffire à elles-mêmes : l'information sur le contexte et la provenance des données - comment et pourquoi elles ont été créées, quels objets et concepts du monde réel elles représentent, les contraintes sur les valeurs - est nécessaire pour aider les utilisateurs à les interpréter de façon responsable.
Structurer les métadonnées sur les jeux de données sous une forme standardisée et lisible par un programme encourage la promotion, le partage et la réutilisation des données.
Le partage des données sensibles et des données propriétaires
Avec une planification appropriée de la gestion des données, beaucoup de données sensibles et propriétaires peuvent être partagées, réutilisées et FAIR. Les métadonnées peuvent presque toujours être partagées. Les guides et les bonnes pratiques en matière de partage des données sensibles sont nécessairement propres à chaque région en raison de réglementations différentes (voir par exemple le Companion material for Managing and Sharing Research Data handbook) de UKDS. L'Association Internationale pour les services et Technologies de l'Information en Sciences Sociales tient une liste d'orientations internationales en matière de gestion des données qui constitue un bon point de départ. Il existe plusieurs approches et initiatives pour aider les chercheurs à atteindre cet objectif. L'outil DMPonline du Digital Curation Centre comprend un certain nombre de modèles pour les financeurs. Le guide CESSDA Expert Tour Guide on Data Management fournit des informations et des exemples pratiques sur la manière de partager des données personnelles , sur les questions de droits d'auteur et de bases de données dans les pays européens. Le Tour Guide donne également un aperçu de l'impact du RGPD qui harmonise la législation sur les données personnelles en Europe (depuis mai 2018), et fournit un aperçu actualisé sur la diversité de l'UE en matière de protection des données.
Les Courtiers en données
Les courtiers en données sont des parties bien informées et indépendantes qui agissent en tant que gardiens des données sensibles. Les chercheurs peuvent transférer au courtier leurs données sensibles et leur juridiction sur l'accès à ces données. Cette situation est particulièrement fréquente dans le cas des données sur les patients provenant d'études cliniques. Les courtiers assurent un certain degré d'indépendance dans l'évaluation des demandes de données qui sont scientifiquement valides et qui ne porteront pas atteinte à la vie privée des participants à la recherche. Voici des exemples de courtiers en données : The YODA Project, ClinicalStudyDataRequest.com, National Sleep Research Resource et Supporting Open Access for Researchers (SOAR).
Les Portails d'analyse
Les portails d'analyse sont des plates-formes qui permettent l'analyse approuvée des données sans pour autant permettre un accès total (visualisation ou téléchargement) ni contrôler où et qui a accès à celles-ci. Certains courtiers en données utilisent également des portails d'analyse. Les portails d'analyse contrôlent quels jeux de données supplémentaires peuvent être ajoutées aux données sensibles, ainsi que les analyses qui peuvent être effectuées afin de s'assurer que les renseignements personnels ne sont pas révélés pendant une nouvelle analyse. Parmi les exemples de portails d'analyse virtuelle, on peut citer Project Data Sphere, Vivli, RAIRD, et INESS.
Les chercheurs en sciences sociales et les autres chercheurs en possession de données sensibles utilisent un portail d'analyse unique auquel on ne peut accéder que de façon contrôlée. Les chercheurs approuvés peuvent accéder aux données sur site, dans une salle sécurisée, à des fins scientifiques. Toutefois, les métadonnées décrivant les données devraient être librement accessibles et conformes aux principes FAIR.
Données anonymisées et données synthétiques
De nombreux jeux de données contenant des informations privées au niveau du participant peuvent être partagés une fois que l'ensemble de données a été anonymisé (méthode Safe Harbor) ou qu'un expert a déterminé que le jeu de données n'est pas individuellement identifiable (méthode Expert Determination). Consultez votre comité d'éthique de la recherche pour savoir comment procéder en la matière avec vos données. Nous recommandons également le guide CESSDA Expert Tour Guide on Data Management, qui fournit des informations et des exemples pratiques sur la façon de partager des données personnelles. Toutefois, certains jeux de données ne peuvent être anonymisés et partagés en toute sécurité. Les chercheurs peuvent encore améliorer la transparence de la recherche sur ces données en créant et en partageant des données synthétiques. Les données synthétiques ont une structure, un contenu et une distribution similaires aux données réelles et visent à atteindre une "validité analytique" : l'analyse statistique donnera les mêmes résultats pour les données synthétiques que les données réelles. Le Bureau de Recensement des États-Unis, par exemple, utilise des données synthétiques et des portails d'analyse en association pour permettre la réutilisation de données hautement sensibles.
DataTags
DataTags est un cadre conçu pour permettre des évaluations assistées par ordinateur des restrictions légales, contractuelles et politiques régissant les décisions relatives au partage des données. Le système DataTags pose à l'utilisateur une série de questions pour connaître les propriétés clés d'un jeu de données spécifique et applique des règles d'inférence pour déterminer les lois, les contrats et les meilleures pratiques applicables. Le résultat est un ensemble de DataTags recommandés, ou de simples étiquettes sous forme d'icônes qui représentent une politique de données lisible par l'homme et interprétable par la machine, ainsi qu'un accord de licence adapté au jeu de données individuel. Le système DataTags est conçu pour s'intégrer au logiciel de l'entrepôt de données et fonctionnera également comme un outil autonome. DataTags est en cours de développement à l'Université de Harvard. En Europe, DANS travaille sur l'adaptation de DataTags à la législation européenne / Règlement général sur la protection des données (RGPD (cf. DANS GDPR DataTags).
Comme nous l'avons mentionné ci-dessus, le but ultime du partage de vos données de recherche est de les rendre réutilisables au maximum. À cette fin, avant de partager vos données, vous devez les gérer en appliquant les meilleures pratiques. Cela inclut, entre autres : la documentation et le choix de formats de fichiers ouverts et de licences ouvertes. Pour en savoir davantage sur ces questions, consultez la Section 4: Recherche reproductible et Analyse des Données et la Section 6: Licences et Formats de Fichiers Ouverts
Matériels ouverts
Outre le partage des données, l'ouverture de la recherche repose sur le partage des matériels. Les matériels utilisés par les chercheurs sont propres à une discipline et parfois spécifiques à un laboratoire. Vous trouverez ci-dessous des exemples de matériels que vous pouvez partager, bien que vous puissiez toujours vous entretenir avec les pairs de votre discipline pour déterminer quels entrepôts y sont utilisés. Lorsque vous avez des matériels, des données et des publications d'un même projet de recherche partagés dans différents entrepôts, référencez-les avec un lien et un identifiant unique pour qu'ils puissent être facilement localisés.
Les Réactifs
Un réactif est une substance, un composé ou un mélange qui peut être ajouté à un système afin de créer une réaction chimique ou une réaction d'un autre type. Les réactifs peuvent être déposés dans des entrepôts tels que Addgene, The Bloomington Drosophila Stock Center, et ATCC pour les rendre facilement accessibles aux autres chercheurs. Obtenez une licence pour vos supports afin qu'ils puissent être réutilisés par d'autres chercheurs.
Les Protocoles
Un protocole décrit un enregistrement formel ou officiel des observations expérimentales scientifiques sous un format structurée. Déposez des protocoles virtuels pour la citation, l'adaptation et la réutilisation à l'aide de Protocols.io.
Carnets de recherche, conteneurs, logiciels et matériel informatique
L'analyse reproductible est facilitée par l'utilisation de la programmation lettrée, de la technologie des conteneurs et de la virtualisation. En plus de partager votre code et vos données, partagez également vos Jupyter Notebooks, vos images Docker ou tout autre matériel d'analyse ou dépendances logicielles. Partagez vos carnets de recherche avec des services ouverts tels que mybinder qui permettent au public de visualiser et d'exécuter l'intégralité du carnet de recherche sur des ressources partagées. Les conteneurs et les notebooks peuvent être partagés avec Rocker ou Code Ocean. Les logiciels et le matériel utilisés dans le cadre de votre recherche doivent être partagés conformément aux pratiques exemplaires en matière de documentation décrites dans la Section 3. Les protocoles en lecture seule doivent être déposés dans le registre de votre discipline comme ClinicalTrials.gov et SocialScienceRegistry,ou un registre général comme Open Science Framework. De nombreuses revues, telles que Trials, JMIR Research Protocols, ou Bio-Protocol, publieront votre protocole. Les meilleures pratiques pour la publication de votre protocole en accès libre sont les mêmes que pour la publication de votre rapport en accès libre (voir Section 5).
Questions, obstacles et idées fausses courantes
Q : "Est-il suffisant de rendre mes données librement accessibles ?"
R : "Non - L'ouverture est une condition nécessaire mais non suffisante pour une réutilisation maximale. Les données doivent être FAIR en plus d'être ouvertes."
Q : "Que signifient les principes FAIR pour les différentes acteurs/publics ?"
R : "C'est un excellent sujet de discussion !"
Obstacle : Les chercheurs peuvent être réticents à partager leurs données parce qu'ils craignent que d'autres ne les réutilisent avant qu'ils aient pu en tirer le maximum, ou que d'autres ne comprennent pas entièrement leurs données et les utilisent à mauvais escient.
(Suggestion) A : Vous pouvez publier vos données pour les rendre "faciles à trouver" avec les métadonnées, mais établissez au préalable une période d'embargo sur ces données pour vous assurer de publier votre (vos) propre(s) article(s) en premier.
Q : "Est-ce que le fait de rendre mes données FAIR représente beaucoup de travail supplémentaire ?"
R : "Pas nécessairement ! Rendre les données FAIR n'est pas seulement de la responsabilité de chercheurs individuels, mais aussi de celle de l'ensemble du groupe. La meilleure façon de vous assurer que vos données sont FAIR est de créer un plan de gestion des données et de tout planifier à l'avance. Pendant la collecte et le traitement des données, suivez les normes et les mesures disciplinaires recommandées par un référentiel.
Q : "Je veux partager mes données. Comment devrais-je les inscrire sous une licence ?"
R : "C'est une bonne question. Tout d'abord, à qui appartiennent les données ? À un bailleur de fonds de la recherche ou à un établissement pour lequel vous travaillez ? Ensuite, pensez à la paternité de l'œuvre. L'application d'une licence appropriée à vos données est cruciale afin de les rendre réutilisables. Pour plus d'informations sur les licences, voir 6. Licences Ouvertes et Formats de Fichiers.
Q : " Je ne peux pas rendre mes données directement accessibles - elles sont trop volumineuses pour être partagées de façon pratique / elles comportent des restrictions relatives à la vie privée. Que dois-je faire ?"
R : "Adressez-vous à des experts en référentiels spécifiques à un domaine, pour qu'ils vous fournissent des instructions suffisantes pour rendre vos données faciles à trouver et accessibles".
Acquis de la formation
Comprendre les caractéristiques des données ouvertes et en particulier les principes FAIR.
Se familiariser avec certains des arguments en faveur et contre les données ouvertes.
Être capable de différencier et de traiter des données sensibles et des données opFAIR ; ces deux catégories ne sont pas nécessairement incompatibles.
Être capable de transformer un jeu de données en un jeu suffisant pour le partage ouvert (format non-propriétaire), le rendre conforme aux principes FAIR, et en maximiser l'accessibilité, la transparence et la réutilisation en fournissant suffisamment de métadonnées.
Connaître la différence entre données brutes et données traitées (ou nettoyées) et l'importance des étiquettes de version.
Connaître les formats de fichiers couramment utilisés et les normes de la communauté pour une réutilisation optimale.
Être capable de rédiger un plan de gestion des données.
Lectures complémentaires
Averkamp et al. (2018). Data packaging guide. github.com/saverkamp/beyond-open-data/blob/master/DataGuide.md.
Barend et al. (2017). Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. doi.org/10.3233/ISU-170824
Brase et al. (2009). Approach for a joint global registration agency for research data. doi.org/10.3233/ISU-2009-0595
Candela et al. (2015). Data journals: A survey. doi.org/10.1002/asi.23358
CESSDA Training Working Group (2017-2018a). CESSDA Data Management Expert Guide. Bergen, Norway: CESSDA ERIC. cessda.eu/DMGuide
CESSDA Training Working Group (2017-2018b). CESSDA Data Management Expert Guide: Citing your data. Bergen, Norway: CESSDA ERIC.cessda.eu/DMGuide/citingdata
FAIRsharing.org (2016). FAIR. The FAIR Principles. doi.org/10.25504/FAIRsharing.WWI10U
Force 11 (n.y.). Guiding principles for Findable, Accessible, Interoperable, and Re-usable data publishing Version B1.0. force11.org/fairprinciples
Gorgolewski et al. (2013). Making data sharing count: a publication-based solution. doi.org/10.3389/fnins.2013.00009
Kratz and Strasser (2015). Making Data Count. doi.org/10.1038/sdata.2015.39
Piwowar and Vision (2013). Data reuse and the open data citation advantage. doi.org/10.7717/peerj.175
Wilkinson et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. doi.org/10.1038/sdata.2016.18
Wilkinson et al. (2918). A design framework and exemplar metrics for FAIRness. doi.org/10.1038/sdata.2018.118
Initiatives et projets
DataTags DANS GDPR : zingtree.com
Métrique FAIR : fairmetrics.org
Initiative GO FAIR : go-fair.org
Les principes des données FAIR expliqués : go-fair.org
5★ OPEN DATA. 5stardata.info