2. Dados e Materiais de Investigação Abertos
O que são?
Dados de investigação abertos são dados que podem ser livremente acedidos, reutilizados, remisturados e redistribuídos, para efeitos de investigação académica e ensino e outros fins. Idealmente, os dados abertos não têm restrições de reutilização ou redistribuição, e têm licenças apropriadas para tal. Em casos excecionais, por exemplo para proteção de identidade de pessoas, são estabelecidas restrições especiais ou limitadas de acesso. Partilhar abertamente os dados expõe-nos à inspeção, o que constitui a base para a verificação e reprodutibilidade da investigação, e abre o caminho para a mais ampla colaboração. No máximo, os dados abertos podem estar sujeitos ao requisito de atribuição e partilha de modo igual (ver Open Data Handbook).
Fundamentação
Os dados de investigação são frequentemente o resultado mais valioso de muitos projetos de investigação, são usados como fontes primárias que sustentam a investigação científica e possibilitam a derivação de descobertas teóricas ou aplicadas. De forma a tornar descobertas/estudos replicáveis, ou pelo menos reprodutível ou reutilizável (referência à Investigação Reprodutível e Análise de Dados) de qualquer outra forma, a recomendação de boas práticas para os dados de investigação é serem o mais abertos e FAIR possíveis, tendo em conta os constrangimentos éticos, comerciais e de privacidade de dados sensíveis ou dados proprietários.
Objetivos de aprendizagem
Compreender as características e princípios básicos dos dados de investigação abertos e FAIR, incluindo o empacotamento e documentação apropriados, para permitir que outros entendem, reproduzam, e reutilizem de formas alternativas.
Familiaridade com os tipos de dados que podem ser considerados sensíveis, e as restrições ou constrangimentos de os partilhar abertamente.
Ser capaz de converter um conjunto de dados 'fechados' em 'aberto' implementando as medidas necessárias num plano de gestão de dados, com a administração dos dados e metadados apropriados.
Ser capaz de usar planos de gestão de dados e tornar os seus resultados de investigação localizáveis e acessíveis, mesmo que contenham dados sensíveis.
Compreender os prós e contras de partilhar abertamente diferentes tipos de dados (ex., privacidade, sensibilidade, anonimização, acesso mediado).
Compreender a importância de metadados apropriados para o arquivo sustentável dos dados de investigação.
Compreender os fluxos de trabalho básicos e as ferramentas para partilha de dados de investigação.
Componentes-chave
Conhecimento & Capacidades
Princípios FAIR
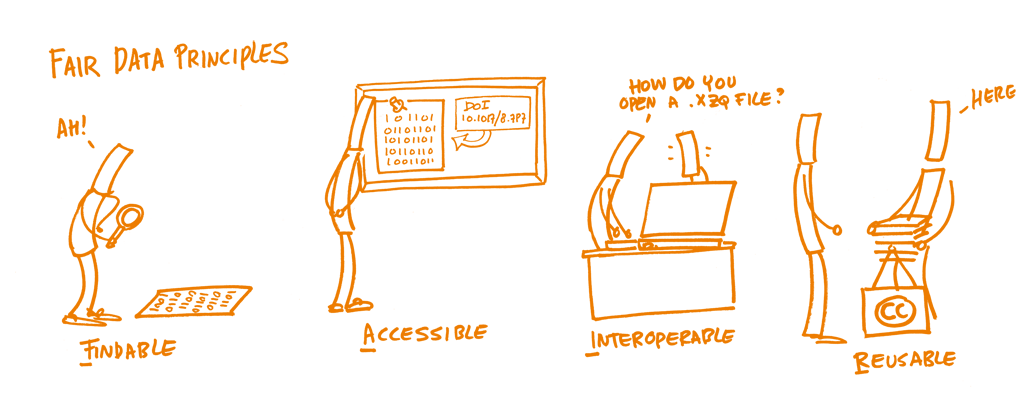
Em 2014, foi elaborado um conjunto de princípios básicos de forma a otimizar a reutilização de dados de investigação, a que foi dados o nome de Princípios para Dados FAIR. Representam um conjunto de normas e boas práticas desenvolvidas pela comunidade para assegurar que os dados ou qualquer objeto digital são Findable (localizáveis), Accessible (acessíveis), Interoperable (interoperáveis) e Re-usable (reutilizáveis):
Findable: O primeiro requisito para tornar os dados reutilizáveis é a possibilidade de os encontrar. Deve ser fácil encontrar os dados e os metadados tanto para humanos como para computadores. A descoberta automática e fiável de conjuntos de dados e serviços depende de identificadores persistentes legíveis por máquinas (PIDs) e de metadados.
Accessible: Os (meta)dados devem ser recuperáveis pelo seu identificador utilizando um protocolo de comunicações padronizado e aberto, possivelmente incluindo autenticação e autorização. Além disso, os metadados devem estar disponíveis mesmo quando os dados já não estão.
Interoperable: Os dados devem poder ser combinados e usados com outros dados ou ferramentas. O formato dos dados deve ser aberto e interpretável por várias ferramentas, incluindo outros registos de dados. O conceito de interoperabilidade aplica-se tanto aos dados como aos metadados. Por exemplo, os (meta)dados devem usar vocabulários que sigam os princípios FAIR.
Re-usable: Em última instância, FAIR tem o objetivo de otimizar a reutilização dos dados. Para isso, os metadados e os dados devem estar bem descritos para que possam ser replicados e/ou combinados em diferentes contextos. Além disso, a reutilização dos (meta)dados deve estar declarada através de (uma) licença(s) clara(s) e acessível(eis).
Ao contrário de iniciativas similares que se concentram no investigador, os princípios FAIR dão ênfase ao aumento da capacidade das máquinas automaticamente encontrarem e usarem os dados ou qualquer objeto digital, além de apoiar a sua reutilização por pessoas. Os princípios FAIR são princípios orientadores, não normas. Os FAIR descrevem qualidades ou comportamentos necessários para tornar os dados reutilizáveis ao máximo. (ex., descrição, citação). Estas qualidades podem ser atingidas através de diferentes normas.
Publicação de dados
A maioria dos investigadores está mais ou menos familiarizada com a publicação em Acesso Aberto de artigos de investigação e de livros (ver capítulo 5). Mais recentemente, e pelas razões mencionadas acima, a publicação de dados ganhou uma atenção crescente. Cada vez mais financiadores esperam que os dados produzidos em projetos de investigação que financiam fiquem localizáveis, acessíveis e tão abertos quanto possível.
Existem várias formas de tornar os dados de investigação acessíveis, incluindo (Wikipedia):
Publicar os dados como material suplementar associado a um artigo de investigação, geralmente com os ficheiros de dados disponíveis junto do artigo no site da editora.
Inserir os dados num site disponível publicamente, com os ficheiros disponíveis para download.
Depositar os dados num repositório que tenha sido desenvolvido para apoiar a publicação de dados, ex., Dataverse, Dryad), Figshare, Zenodo.
Existe um grande número de repositórios gerais ou de domínios específicos que podem fornecer apoio adicional aos investigadores no processo de depósito dos seus dados.
Publicar um artigo de dados sobre o conjunto de dados, que pode ser publicado como preprint, numa revista científica, ou numa revista de dados que é dedicada a artigos de dados. Os dados podem ser alojados na revista ou separadamente num repositório de dados. Exemplos de revistas de dados incluem Scientific Data (da SpringerNature) e Data Science Journal (da CODATA). Para uma revisão abrangente das revistas de dados, ver Candela et al.
O CESSDA ERIC Expert tour guide on Data Management fornece uma visão geral dos prós e contras de diferentes vias de publicação de dados. Por vezes, o seu financiador ou outra entidade externa requere que use um repositório específico. Se tiver liberdade de escolha, pode considerar a ordem de preferência nas recomendações do OpenAIRE:
- Use um arquivo de dados externo ou um repositório já estabelecido para a sua área de investigação para preservar os dados de acordo com os padrões reconhecidos na sua disciplina ou domínio de investigação.
- Se disponível, use um repositório institucional de dados de investigação, ou os recursos de gestão de dados estabelecidos pelo seu grupo de investigação.
- Use um repositório de dados gratuito tal como Dataverse, Dryad, figshare ou Zenodo.
- Procure outros repositórios de dados em re3data. Não existe um filtro único no re3data que cubra os princípios FAIR, mas considere as seguintes opções de filtros para o ajudar a encontrar repositórios compatíveis com os princípios FAIR: categorias de acesso, licenças de uso dos dados, repositórios de dados confiáveis (com certificado ou com adesão explícita a padrões de arquivo ) e se o repositório atribui um identificador persistente (PID) aos dados. Outro aspeto a considerar é se o repositório suporta versionamento.
Deve considerar onde depositar e publicar os seus dados logo no seu plano de gestão de dados. O CESSDA oferece algumas questões práticas, que se recomendaconsiderar. Por exemplo: Que dados e metadados associados, documentação e código serão depositados? Quanto tempo é necessário conservar os dados? Por quanto tempo os dados devem permanecer reutilizáveis? Como vão estar disponíveis os dados? Que categoria de acesso vai escolher? Para mais questões veja Adapt your DMP: part 6. Por outro lado, não se esqueça de verificar se o repositório que escolheu preenche os requisitos da sua investigação e do seu financiador. Alguns repositórios obtiveram certificação, tal como CoreTrustSeal, que certifica os repositórios como confiáveis e que preenchem os requisitos de Core Trustworthy Data Repositories. Vale a pena mencionar que alguns repositórios disciplinares de áreas específicas podem aceitar apenas dados com alta qualidade com potencial de reutilização e que podem ser partilhados publicamente.
Uma vez que existem vários formas de publicar os seus dados, deve notar que para um conjunto de dados "contar" como uma publicação, deve seguir um processo de publicação similar ao de um artigo (Brase et al., 2009) e deve ser:
Devidamente documentado com metadados;
Revisto quanto à qualidade, ex. conteúdo do estudo, metodologia, relevância, consistência legal e documentação de materiais;
Pesquisável e localizável em catálogos (ou bases de dados);
Citável em artigos.
Citação de dados
Serviços de citação de dados ajudam as comunidades de investigação a encontrar, identificar e citar dados de investigação (e frequentemente outros objetos de investigação) com confiança. Normalmente isto envolve a criação e atribuição de Digital Object Identifiers (DOIs), e dos metadados que os acompanham através de serviços como DataCite (https://www.datacite.org), e pode ser integrado nos fluxos de trabalho e padrões de investigação. Este é um campo emergente, e envolve aspetos como transmitir aos editores de revistas científicas a importância da citação de dados apropriada nos artigos, bem como permitir que os artigos científicos sejam ligados a quaisquer dados subjacentes que lhe deram origem. Através disto, os dados citáveis tornam-se contribuições legítimas para o processo de comunicação académica, e podem ajudar a pavimentar o caminho para novas métricas e modelos de publicação que reconheçam e premeiem a partilha de dados.
Como passo inicial em direção às boas práticas para a citação de dados, o Data Citation Synthesis Group da FORCE11 apresentou a Joint Declaration of Data Citation Principles, direcionado tanto para investigadores como para fornecedores de serviços de dados. Ao aderir a estes princípios, os repositórios de dados geralmente oferecem aos investigadores uma referência que podem usar ao referir-se a um determinado conjunto de dados.
Empacotamento de dados
Pacotes de dados são recipientes para a descrição e partilha dos ficheiros de dados acompanhantes, e geralmente incluem um ficheiro de metadados descrevendo as características e contexto de um conjunto de dados. Isto pode incluir aspetos como informação da criação, proveniência, tamanho, formato, definições da área, bem como quaisquer ficheiros contextuais relevantes, como scripts de criação de dados ou documentação textual. Do Data Packaging Guide:
Os dados são eternos: os conjuntos de dados sobrevivem ao seu propósito original. Limitações dos dados podem ser óbvias no seu contexto original, tal como um catálogo de biblioteca, mas podem não ser evidentes quando os dados são separados da aplicação em que foram criados.
Os dados não são suficientes por si próprios: Informação sobre o contexto e proveniência dos dados--como e porque foram criados, que objetos do mundo real e conceitos representam, as restrições de valores--é necessária para ajudar os consumidores a interpretá-los de forma responsável.
Estruturar metadados sobre conjuntos de dados de uma for,ma padronizada e legível por máquinas encoraja a promoção, partilha, e reutilização dos dados.
Partilhar dados sensíveis e dados proprietários
Com um plano de gestão de dados apropriado muitos dados sensíveis e proprietários podem ser partilhados, reutilizados, e tornados FAIR. Os metadados podem quase sempre ser partilhados. As orientações e boas práticas para partilha de dados sensíveis são necessariamente específicos de cada região devido a diferentes regulamentações (ver por exemplo UKDS’Companion material for Managing and Sharing Research Data handbook). A International Association for Social Science Information Services and Technology tem uma lista de orientações internacionais em gestão de dados que é um bom ponto de partida. Existem várias abordagens e iniciativas para ajudar os investigadores a alcançar este objetivo. A ferramenta DMPonline do DCC inclui vários modelos para os financiadores. O CESSDA Expert Tour Guide on Data Management fornece informação e exemplos práticos de como partilhar dados pessoais e sobre questões de direitos de autor e bases de dados nos países europeus. O Tour Guide oferece ainda uma visão geral do impacto do RGPD que harmoniza a legislação relativa aos dados pessoais na Europa (Maio de 2018), e fornece uma visão atualizada sobre a diversidade de proteção de dados na UE.
Intermediários de dados
Intermediários de dados (data brokers) são entidades especializadas e independentes que agem como administradores de dados para dados sensíveis. Os investigadores podem transferir os seus dados sensíveis e a jurisdição sobre o acesso a esses dados para o intermediário. Isto é especialmente comum nos dados ao nível do paciente em estudos clínicos. Os intermediários fornecem um nível de independência na avaliação de quais pedidos de dados são cientificamente válidos e não irão violar a privacidade dos participantes na investigação. Exemplos de intermediários de dados incluem o Projeto YODA, ClinicalStudyDataRequest.com, National Sleep Research Resource e Supporting Open Access for Researchers (SOAR).
Portais de análise
Portais de análises são plataformas que permitem análise de dados aprovada sem permitir acesso completo (visualização ou download) ou controlar onde e quem tem acesso. Alguns intermediários de dados também usam estes portais de análise. Os portais de análise controlam que conjuntos de dados adicionais podem ser agrupados com os dados sensíveis, bem como que análises podem ser executadas para assegurar que as informações pessoais não são reveladas durante a reanálise. Exemplos de portais de análise virtuais incluem Project Data Sphere, Vivli, RAIRD, Corpuscle, e INESS.
Os investigadores de ciências sociais e outros investigadores com dados sensíveis usam um portal de análise de localização singular que apenas permite o acesso de forma controlada. Os investigadores aprovados podem aceder aos dados in situ, numa sala segura, para propósitos científicos. No entanto, os metadados que descrevem os dados devem estar disponíveis abertamente e cumprir os princípios FAIR.
Dados anonimizados e sintéticos
Muitos conjuntos de dados contendo informação privada dos participantes podem ser partilhados assim que os conjuntos de dados forem anonimizados (Método Safe Harbour) ou um especialista tiver determinado que o conjunto de dados não permite a identificação individual (Método Expert Determination). Consulte o seu Conselho de Ética em Investigação / Conselho de Revisão Institucional para saber mais sobre como proceder desta forma com os seus dados. Também recomendamos o CESSDA Expert Tour Guide on Data Management, que fornece informação e exemplos práticos sobre como partilhar dados pessoais. No entanto, alguns conjuntos de dados não podem ser anonimizados e partilhados de forma segura. Os investigadores podem ainda assim melhorar a abertura da investigação neste tipo de dados ao criar e partilhar dados sintéticos. Os dados sintéticos têm uma estrutura, conteúdo, e distribuição similares aos dados reais e visam atingir a "validade analítica": a análise estatística obterá os mesmos resultados para os dados sintéticos como para os dados reais. O Departamento de Censos dos Estados Unidos, por exemplo, usa dados sintéticos e portais de análise em combinação com a permissão de reutilização de dados altamente sensíveis.
DataTags
DataTags é uma estrutura que permite avaliações assistidas por computador de restrições legais, contratuais e políticas que regem as decisões sobre a partilha de dados. O sistema DataTags pergunta ao utilizador uma série de questões para extrair as propriedades principais de um dado conjunto de dados e aplica regras inferidas para determinar que leis, contratos, e boas práticas são aplicáveis. O resultado é um conjunto de DataTags recomendadas, ou etiquetas simples e icónicas que representam uma política de dados legível por humanos e acionável por máquinas, e uma licença que é fabricada para um conjunto de dados específico. O sistema de DataTags tem sido desenhado para ser integrado com o softwares de repositórios de dados, e funcionará também como ferramenta independente. DataTags está a ser desenvolvido na Universidade de Harvard. Na Europa, a DANS está a trabalhar em ajustar DataTags à legislação Europeia / Regulamento Geral de Proteção de Dados (RGPD) (cf. DANS RGPD DataTags).
Como foi referido anteriormente, o derradeiro objetivo da partilha de dados da sua investigação é torná-los reutilizáveis ao máximo. Para atingir esse objetivo, antes de partilhar os dados terá que os gerir de acordo com as boas práticas. Isto inclui, entre outras coisas, documentação e escolha de formatos de ficheiros abertos e licenças. Pode ler mais sobre este assunto no Capítulo 2.4: Investigação Reprodutível e Análise de Dados bem como no Capítulo 2.6: Licenças Abertas e Formatos de Ficheiros.
Materiais Abertos
Além da partilha dos dados, a abertura da investigação depende da partilha de materiais. Os materiais que os investigadores usam são específicos para cada disciplina e por vezes exclusivos de um laboratório. Abaixo encontrará exemplos de materiais que pode partilhar, apesar de sempre dever consultar os colegas da sua área de conhecimento sobre que repositórios são utilizados. Quando tiver materiais, dados, e publicações do mesmo projeto de investigação partilhados em diferentes repositórios, assegure-se de fazer referência cruzada com uma ligação e um identificador único para que possam ser facilmente localizados.
Reagentes
Um reagente é uma substância, composto ou mistura que pode ser adicionado a um sistema de forma a criar uma reação química ou outra. Os reagentes podem ser depositados em repositórios como Addgene, The Bloomington Drosophila Stock Center, e ATCC para torná-los facilmente acessíveis por outros investigadores. Atribua-lhes uma licença para que possam ser reutilizados por outros investigadores.
Protocolos
Um protocolo descreve um registo formal ou oficial de observações científicas experimentais num formato estruturado. Deposite protocolos virtuais para citação, adaptação, e reutilização usando Protocols.io.
Notebooks, containers, software, e hardware
As análises reprodutíveis são facilitadas pelo uso de programação documentada, tecnologia de containers, e virtualização. Além de partilhar o seu código e os seus dados, também pode partilhar os seus notebooks Jupyter, imagens Docker, ou outros materiais de análise ou dependências de software. Partilhe notebooks através de serviços abertos como mybinder que permite visualização pública e execução de todo o notebook em recursos partilhados. Containers e notebooks podem ser partilhados com Rocker ou Code Ocean. Software e hardware usados na sua investigação devem ser partilhados seguindo as boas práticas para documentação como foi definido no Capítulo 2.3. Os protocolos apenas para leitura devem ser depositados no registo da sua área do conhecimentos tal como ClinicalTrials.gov e SocialScienceRegistry](https://www.socialscienceregistry.org/) ou em um registo geral como Open Science Framework. Várias revistas científicas, como a Trials, a JMIR Research Protocols, ou a Bio-Protocol, irão publicar o seu protocolo. As boas práticas para a publicação em acesso aberto do seu protocolo são as mesmas que para publicar o seu relatório em acesso aberto (ver Capítulo 2.5).
Perguntas, obstáculos, e equívocos comuns
P: "É suficiente disponibilizar os meus dados em acesso aberto?"
R: "Não—a abertura é uma condição necessária mas não suficiente para a reutilização máxima. Os dados além de serem abertos, têm de ser FAIR."
P: "O que significam/implicam os princípios FAIR para diferentes partes interessadas / públicos?"
R: "Esse é um excelente assunto para discussão!"
Obstáculo: Os Investigadores podem sentir-se hesitantes a partilhar os seus dados porque têm medo que outros os reutilizem antes que eles possam extrair o máximo uso possível dos seus dados, ou que outros possam não entender completamente os dados e os que utilizem de forma incorreta.
(sugerido) R: Pode publicar os seus dados e torná-los acessíveis através de metadados, mas atribua-lhes um período de embargo para se assegurar que publica o(s) seu(s) artigo(s) primeiro.
P: "Tornar os meus dados FAIR constitui trabalho extra?"
R: "Não necessariamente! Tornar os dados FAIR não é responsabilidade só dos investigadores como indivíduos mas de todo o grupo. A melhor forma de assegurar-se que os seus dados são FAIR é criar um Plano de Gestão de Dados e planear tudo de antemão. Durante a recolha dos dados e o processamento dos dados siga os normas da sua área de conhecimento e as medidas recomendadas por um repositório.
P: "Eu quero partilhar os meus dados. Que licença devo atribuir-lhes?"
R: "Essa é uma boa pergunta. Em primeiro lugar pense: quem é o proprietário dos dados? Um financiador de investigação ou a instituição para quem trabalha? Depois, pense na autoridade. Aplicar a licença adequada aos seus dados é crucial para os tornar reutilizáveis. Para mais informação sobre licenças, veja 6. Licenciamento Aberto e Formatos de Ficheiros.
P: "Eu não posso tornar os meus dados disponíveis diretamente—são muito grandes para partilhar de forma conveniente / têm restrições relacionadas com questões de privacidade. Como devo proceder?"
R: "Deve conversar com especialistas em repositórios da sua área do conhecimento sobre como fornecer instruções suficiente para tornar os seus dados localizáveis e acessíveis."
Resultados da aprendizagem
Compreender as características de dados abertos, em especial os princípios FAIR.
Ficar familiarizado com alguns argumentos a favor e contra os dados abertos.
Ser capaz de diferenciar e abordar dados sensíveis e dados FAIR; estas duas categorias não são necessariamente incompatíveis.
Ser capaz de transformar um conjunto de dados de forma a que fique preparado para partilha de forma aberta (formatos não proprietários), cumpra os padrões dos princípios FAIR, e seja desenhados para a acessibilidade, transparência e reutilização maximizada através do fornecimento de metadados suficientes.
Saber a diferença entre dados em brutos e processados (ou limpos), e a importância das etiquetas das versões.
Conhecer formatos de ficheiros frequentemente utilizados e padrões da comunidade para a máxima reutilização.
Ser capaz de redigir um plano de gestão de dados.
Leitura adicional
Averkamp et al. (2018). Data packaging guide. github.com/saverkamp/beyond-open-data/blob/master/DataGuide.md.
Barend et al. (2017). Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. doi.org/10.3233/ISU-170824
Brase et al. (2009). Approach for a joint global registration agency for research data. doi.org/10.3233/ISU-2009-0595
Candela et al. (2015). Data journals: A survey. doi.org/10.1002/asi.23358
CESSDA Training Working Group (2017-2018a). CESSDA Data Management Expert Guide. Bergen, Norway: CESSDA ERIC. cessda.eu/DMGuide
CESSDA Training Working Group (2017-2018b). CESSDA Data Management Expert Guide: Citing your data. Bergen, Norway: CESSDA ERIC.cessda.eu/DMGuide/citingdata
FAIRsharing.org (2016). FAIR. The FAIR Principles. doi.org/10.25504/FAIRsharing.WWI10U
Force 11 (n.y.). Guiding principles for Findable, Accessible, Interoperable, and Re-usable data publishing Version B1.0. force11.org/fairprinciples
Gorgolewski et al. (2013). Making data sharing count: a publication-based solution. doi.org/10.3389/fnins.2013.00009
Kratz and Strasser (2015). Making Data Count. doi.org/10.1038/sdata.2015.39
Piwowar and Vision (2013). Data reuse and the open data citation advantage. doi.org/10.7717/peerj.175
Wilkinson et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. doi.org/10.1038/sdata.2016.18
Wilkinson et al. (2918). A design framework and exemplar metrics for FAIRness. doi.org/10.1038/sdata.2018.118
Iniciativas e projetos
DANS GDPR DataTags. zingtree.com
FAIR Metrics. fairmetrics.org
GO FAIR Initiative. go-fair.org
The FAIR Data Principles explained. go-fair.org
5★ OPEN DATA. 5stardata.info